Introducing Fast-Slow Training
Most post-trained AI systems today face a tradeoff:
They can adapt quickly, or they can learn durably, but usually not both.
In our recent research paper, Learning, Fast and Slow, we argue that this is the wrong framing. The paper introduces Fast-Slow Training (FST), a framework that combines two learning channels:
- fast weights: optimized context that absorbs task-specific lessons quickly
- slow weights: model parameters that improve more gradually over time
Parameter-only RL can improve performance on the current task, but often at the cost model drift from base-model behavior, catastrophic forgetting and reduced plasticity for future tasks. Prompt optimization has the opposite limitation: it adapts quickly, but usually cannot capture the full gains available through weight updates alone.
Fig 1: Slow parameters and fast textual-pool are jointly optimized via FST
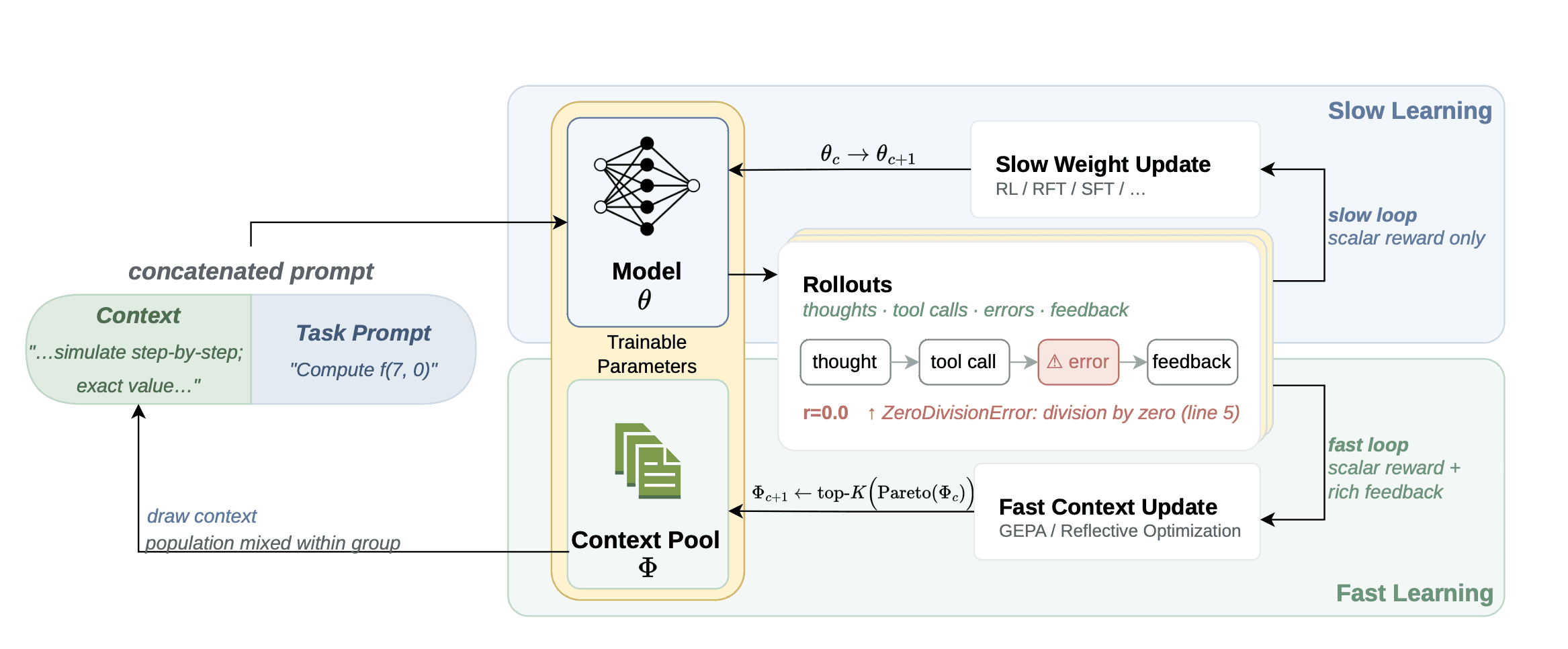
FST combines both. GEPA uses full rollout traces — including reasoning steps, tool calls, mistakes, and verifier feedback — to rewrite prompts based on where the model is succeeding or failing. Training then alternates in cycles. GEPA first improves the prompt population using recent rollouts under the current model. Then, RL takes a batch of gradient steps on the model weights while sampling across that prompt population. In other words, prompt evolution and weight updates are interleaved, not separated into two phases, and both optimize the same reward.
Fig 2: FST beats RL across performance, minimizing plasticity loss, and forgetting
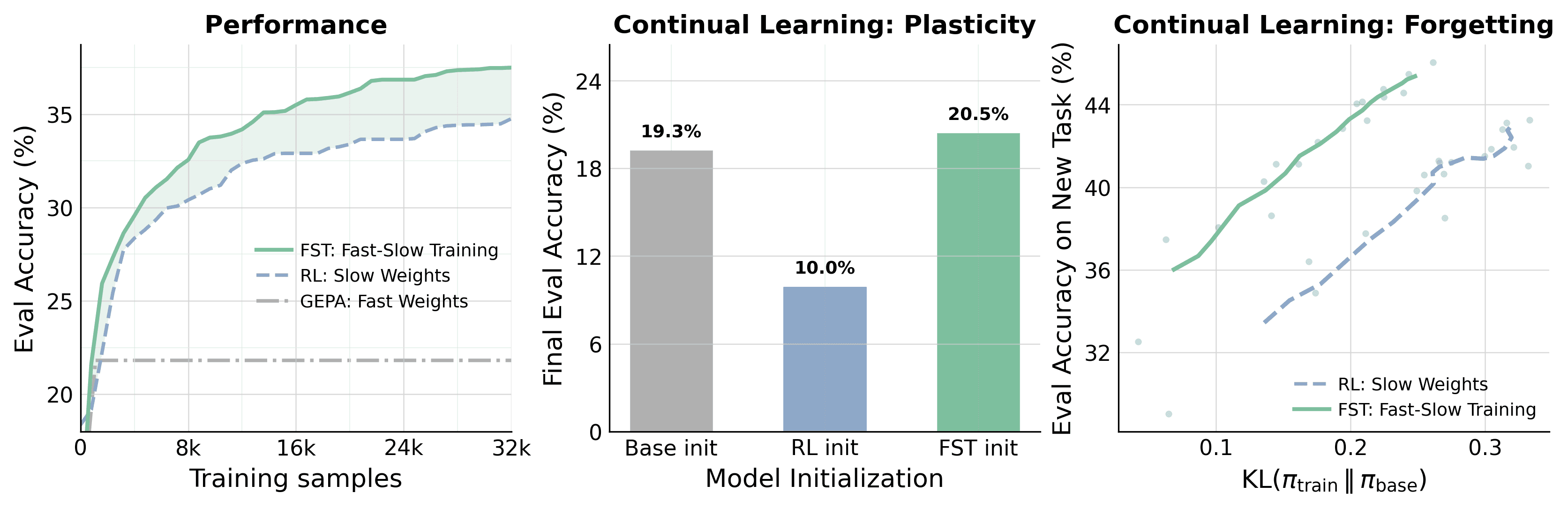
Across reasoning tasks, FST is up to 3x more sample-efficient than RL-only training, reaches a higher final performance ceiling, delivers up to 70% closer to the base model at matched reward, and is better at preserving plasticity in continual learning settings. If AI systems are going to improve continually in real-world environments, they likely need to learn on more than one timescale.
We believe that FST, as a new paradigm of post-training, will serve as the foundational modality for how reinforcement learning should be approached in the future.